見るだけでは発見しづらい機能の解説
目次
- はじめに
- SafariからのWeb取込
- テキストファイル等の取り込み(ことせかい へコピー)
- 本棚の「ひっぱって更新」
- 本文表示部での左右のスワイプ
- イヤホンについたリモコンからの操作
- コントロールセンターでの再生中の再生位置変更
- 読み替え辞書登録Tips
- 読み上げ時の間の設定について
- 読み替え辞書のリストを取り出す
- 巨大なテキストファイルの取り込み方
- 文章側で補佐しながら話者を変える
はじめに
ことせかい の機能は、見れば発見できるように作ろうとしている(長押しや画面外からのスワイプなどの見えていない何かを使うようなものは極力避けたUIを実装しようとしている)のですが、それでも発見しづらい機能がいくつか存在してしまっています。このページではそれら気づかれにくい機能について解説することで、それらの機能が忘れ去られないようにしようかと思います。
なお、このリストは開発者がテキトーに思いつくままに書いているため、全ての発見しづらい機能を網羅しているわけではありません。ですので、何か抜けている物があったり、これは開発者も気づいていないのではなかろうかと思ったりした「便利な使い方」などありましたら、お問い合わせフォーム等からこっそり教えて頂けると嬉しいです。
SafariからのWeb取込
ことせかい では Web取込 タブから小説を取り込む事ができますが、この Web取込 タブに登録されていないWebサイト様についても小説を取り込む事ができる事があります。 そのようなWebサイト様を一つひとつ Web取込 タブ側でなんとかして表示してブックマークに追加するというのも良いとは思うのですが、Web取込 タブのブラウザはいまいち使い勝手がよろしくありませんので、特に初期から登録されていないWebサイト様については Safari を使った方が楽だという時もあります。 そのような時にはこの Safari からの Web取込 の機能が便利に利用できるかと思います。 この Safari からの Web取込 の方法については、Web取込の解説ページのSafari からの取込に詳しく書かれておりますのでそちらをご参照ください。
ちなみに、google検索のページなどもWeb取込側のブックマークに入れることは可能ですので便利に利用してください。
テキストファイル等の取り込み(ことせかい へコピー)
ことせかい はテキストファイルやリッチテキスト、PDFといった文書ファイルについて、その文書ファイルの中の文字列を取り込む機能があります。これは、iOS のシェア機能を使って実装されています。 例えば、メールに添付されたテキストファイルやDropbox等のオンラインストレージサービス等に保存されたファイルを読み込む場合、それらのファイルをシェアボタン(四角から上向きの矢印が出ているアイコン)を使ってシェアされる先として、「ことせかいへコピー」が出る場合にはそのファイルの中身をテキストファイルとして本棚に登録することができます。
なお、初期状態ではシェアボタンで出てくるメニューに「ことせかいへコピー」が出てこないかもしれません。その場合はシェアボタンを押した時に出てくるリストのうち、カラーのアイコンの部分の一番右側にある「その他」を選択した時に出てくる「ことせかいへコピー」をONにしますと、シェアボタンからの「ことせかいへコピー」の機能が使えるようになると思います。(また、シェアメニューで「ことせかい へ読み込む」というボタンが出てくる事がありますが、こちらは Safari からの取り込み時の専用メニューになりますので恐らくは Safari 以外のアプリでは動作しませんので「ことせかいへ コピー」の方を押して下さい)
なお、2019年2月現在、このようなシェアボタンを経由して ことせかい へと取り込む事ができるファイルは以下の拡張子のものになります。
- .txt
- .rtf, .rtfd
- .html (Version 2.6.3 2022年10月 以降で追加)
本棚の「ひっぱって更新」
ことせかい では、小説が更新された場合にその新しく追加された章を読み込む機能がございます。 本棚を表示している時に右上にあります回転している矢印のアイコンをタップすることで全ての小説について更新の確認を行う事ができますが、小説のリストを一番上までスクロールして、そこからさらに下に向けてリストを引っ張る事でも、全ての小説についての更新の確認を行わせる事ができます。 右上の回転している矢印アイコンをタップするのが面倒くさい場合には少しだけ便利かもしれません。
本文表示部での左右のスワイプ
小説の本文を表示している時に、画面下部の「<」と「>」というアイコンをタップする事で前後の章へと移動できます。 ただ、この「<」と「>」を押すのが面倒くさいという場合には、本文部分を左右にスワイプすることでも、同様に前後の章へと移動することができるようになっています。 どちらか使いやすい方を使って頂ければと思います。
イヤホンについたリモコンからの操作
ことせかい はイヤホンからのリモートコントロールに対応しています。 イヤホンの種類によって操作が異なってしまいますのでこの操作でこうなる、という事を正確に言い表す事はできないのですが、例えばイヤホンジャックのついた iPhone に付属していたイヤホンについているリモコンからの操作ですと、以下のような事ができるようになっています。
- 再生・停止:真ん中ボタンを一回押す
- 次の章:真ん中ボタンを二回素早く押す
- 前の章:真ん中ボタンを三回素早く押す
- 早送り:真ん中ボタンを二回素早く押し、二回目は押しっぱなし
- 巻き戻し:真ん中ボタンを三回素早く押し、三回目は押しっぱなし
コントロールセンターでの再生中の再生位置変更
設定 → 「他のアプリで音楽が鳴っても止まらないように努力する〜」 がONになっていない場合には、読み上げ中にコントロールセンター(ロック画面や画面外の上か下からスワイプすると出てくるアレ)からの制御が可能です。標準状態では再生の停止や前後の章への移動が可能です。
設定 → 「コントロールセンターでの前の章や次の章へのボタンを少し巻き戻し・少し進めるボタンへ変更する」をONにしますと、前後の章への移動はできなくなりますが、ちょっと聞き取りにくかったのでもう一度、といった時に便利な少し巻き戻しという操作ができるようになります。
設定 → 「コントロールセンターに再生時間を表示する〜」をONにしますと、コントロールセンター上で現在読み上げている章のおおよその読み上げ時間が表示されるようになり、同時に表示される再生位置のゲージをつまんで動かすことで、再生位置を(大雑把ですが)移動させる事ができるようになります。
読み替え辞書登録Tips
ことせかい での読み上げ(正確にはAVSpeechSynthesizerでの読み上げ)は、その「ことせかい」という名前の由来にもありますように、思いの外多くの読み間違いが起こります。この読み間違いを修正するために、設定 → 「読みの修正」という機能があるのですが、この読み替えを行わせるときの登録方法のヒントを書き下しておきますので参考にしてください。
読み替え辞書が本文へと適用される時には、読み替え元の文字数が長い方が優先されます。例えば、「宇宙世紀」から「うちゅうせいき」への読み替えと、「宇宙」から「そら」への読み替えの二つが登録されている時に、「宇宙世紀0079」は「うちゅうせいき0079」へと読み替えられますが、「宇宙に移民」は「そらに移民」へと読み替えられます。
読み替えは、読み上げに使われる文字列として読み替え先の文字に置き換わったものが使われる、という事を意識すると良いです。 これは、読み替えた文字列が前後の文字列と合わさる事で別の単語に変化してしまうのに気をつけると言い換えても良いかもしれません。 例えば「地雷」を「じらい」と読み替える設定があった場合に、「地雷原」は「じらい原」と読み替えられてしまい、発音としては「じらいはら」となってしまう場合があるかもしれない、という事を考えておいたほうが良いという事です。 この例の場合は「地雷」を「じらい」と登録した場合は「地雷原」を「じらいげん」と読み替えるものも別途登録しておいたほうが無難だと思われます。
単語の読み替えは ひらがな よりカタカナへ読み替えさせた方が良い事が多いです。 これは、文章中にはカタカナよりも ひらがな の方がよく出てくるため、ひらがな への読み替えを登録していると、前後のひらがなにくっついて別の単語として認識されて読み上げ方が違うように読み上げられてしまう可能性が高まる事を気をつけているという物です。 読み替え先をカタカナにすることでカタカナ部分が別の単語として認識されやすくなるため、前後の ひらがな とくっついて別の単語として認識される可能性を減らせます。 もちろん、単語ではない部分についてはカタカナにせずに ひらがな のままの方が良い場合の方が多いので、単純にカタカナにすれば良いというわけではありません。
発話時に読みかたを間違えている場合のうち、音声合成エンジン側がその単語を知らない場合は、知っている単語に置き換えておけるのならそうした方が良いです。例えば、「目蓋」は知らないので「めぶた」や「めふた」と読んでしまうけれど、「瞼」は知っているようなので「目蓋」の読み替え先としては「瞼」を指定しておく、であるとか、「嗤って」は知らないので「笑って」への読み替えを登録する、などです。そうすると、発話も意味も変わりませんので読み上げ時の混乱の発生を抑えられそうな予感がします。
「は」を「わ」と読み上げさせないようにするには、「歯」に読み替えさせるという手段がないこともありません。 ただ、「歯」が前後の文字列とくっついてしまって別の単語として認識されてしまうことで読みがおかしなことになる場合がありそうです。 この場合に「_歯_」や「"歯"」といった形で前後に「_」や「"」をくっつけることで強制的に前後の文字とはくっつけずに認識させることができるようです。 ただ、このテクニックは iOS のアップデートで AVSpeechSynthesizer が更新されることで上手く動かなくなる可能性があるため、標準の辞書では使っておりません。ご利用の際は将来的におかしな動作になるかもしれないという事を理解した上でご利用下さい。
読み替え先としてカタカナにするにしても、いくつか書き方を変えると読み上げ時のイントネーションが変わる場合があります。例えば「侵入者」を「シンニュウシャ」と読み替えるのと「シンニューシャ」と読み替えるのでは少し発話時のイントネーションが変わったりします。他に、「大賑わい」から「オオニギワイ」と書き換えるよりも、「オオ賑わい」とした方がそれっぽく読み上げてくれたりする、などといった事もあります。ただ、音声合成エンジン側のバージョンアップにより逆によくない読み上げ方になる事も予測されますので、あまり凝った形での読み替えを登録しておくのは良くないかもしれません。とはいえ、「亞人」は音声合成エンジン側が単語を知らないようなので「亜人」と読み替えさせようと思ったけれど、イントネーションが気に食わないので頑張って色々やってみて「阿ジん」とした、などというのは確かにかなり凝ってはいるのですが、今後どうなるか本当にわからないのでどうしたものですかね……(なお「亞人」から「阿ジん」への読み替えは標準の読み替え辞書に入れる予定なので、今後どうなるかちょっと心配です)。
しばらく前から読み替え辞書の登録時には正規表現での登録ができるようになりました。正規表現での読み替えには NSRegularExpression を使っておりますので NSRegularExpression で利用できるオペレータ のほとんどが利用可能です。また、読み替え先の文字列に $1 や $2 といった Template Matching Format を利用することもできます。
他に、正規表現ですと「ひらがな」や「カタカナ」、「漢字」といった文字集合に対しての指定もできるようになっています。それぞれ、
- ひらがな:
\p{Hiragana} - カタカナ:
\p{Katakana} - 漢字:
\p{Han}
他に、正規表現での読み替え指定がされている場合、読み上げを行う文章全体に対して正規表現マッチを行い、マッチした場合には「マッチした部分」から「読み替え先」への読み替え辞書を一時的に登録する、という事を行っています。そのため、読み替えで似た文字列があった場合は一番長い読み替え元の物が採用されるというルールで適用される「読み替え元」は正規表現でマッチした後のマッチした部分になるため、場合によっては推測しにくい挙動になることがありえますのでご注意下さい。
また、「発話変更設定」(会話文等で話者を変えたりする設定)による話者の切り替えが発生する部分をまたぐような読み替え設定は適用されません。具体的には、『彼は「こんにちは」と言った』から、『彼は「さようなら」と言った』という読み替え設定を作成していて、「」による会話文は話者を変更している(声質を変更している)場合には、この読み替え設定は適用されません。 これは、「発話変更設定」による話者の切り替え毎に文字列が分割された後に「読み替え設定」が適用されるためです。 つまり、『彼は「こんにちは」と言った』という文字列は、『彼は』『「こんにちは」』『と言った』という3つの文字列に分割されてから、『彼は「こんにちは」と言った』という読み替え設定を適用しようとされてしまうため、その3つのどれにも適用されない、という動作をする事になります。そのため、「ここからは後書きです。(.*[\r\n]*)*」という正規表現で後書きの全てを適用しようとしたとしても、その後書きの中に会話文として別の話者を利用するような文があった場合などにはこの読み替え設定は適用されなくなる、という動作になります。
なお、上記の「は」を「わ」と読み上げてしまうといった問題がありますため、読み替え先をどう設定しても思ったとおりの読み替えをしてくれないという場合があります。その場合は「設定アプリ」側で設定できる読み替えを使うと、自分の声から生成された発音で読み替えを登録する事ができるので、そちらを使うと回避する事ができる"場合があります"。
こちらは、「設定アプリ」→「アクセシビリティ」→「読み上げコンテンツ」→「読みかた」に読み替えを登録する事で行います。 こちらの読み替えの設定は ことせかい だけではなく iPhone(またはiPad等) の全ての読み上げ時に適用される事になるのですが、この「読みかた」に登録する時に「代替候補」を設定する時に、マイクのマークを押して自分の声で読み替え先を設定できるのです。この自分の声で登録する形にしますと、ことせかい のような普通の文章の文字ではなく、発音記号のような発話情報が生成されて、その発音記号のような発話情報を登録する事ができるわけです。この発音記号のような物が自分の思った「正しい発話」のもので生成されるかどうかはiPhoneがどう認識したかによってしまうのでうまくいかない事も多いのですが、なんとかなる時もありますのでどうしてもうまく設定できないといった場合には試してみてください。
読み上げ時の間の設定について
設定 → 読み上げ時の間の設定 の設定項目について解説しておきます。
読み上げの間の設定は、AVSpeechSynthesizer での読み上げでは「、」や「。」といった部分の間の開け方があまり期待通りな間が開かないというお問い合わせから導入したもので、これらの文字列について、間の開け方をどのくらいにするのか、という事を設定できるようにしたものです。 この間の開け方は、AVSpeechSynthesizer の機能を使った「標準型」と、AVSpeechSynthesizer の仕様のスキマを突いた「非推奨型」の二種類があります。
「標準型」では、AVSpeechUtterance の postUtteranceDelay プロパティを使って間を表現しています。 この postUtteranceDelay は TimeInterval型 で間の時間を指定できるのですが、どうやらある値以下の時間を指定しても、そのある値程度の時間が間として開いてしまうようです。つまり、0.1秒とか0.2秒とかの短い時間は開いてくれるわけですが、0.01秒とかのもっと短い時間の指定をしても0.1秒の間が開いてしまう、という感じです。そのため、ある程度小さい値を指定しようとしても、それ以上の時間の間が開いてしまってあんまり句読点の間に使うには使いにくいのではないか、というものになっています。
これに対して「非推奨型」は、「_。」という文字列を複数回くっつけた文字列を読み上げさせるという手法になっています。AVSpeechSynthesizer では「。」を読み上げるときに、かなり短い時間の間を開けてくれます。これは「標準型」での間の指定よりも短い時間の間を表現できるものです。そこで、「非推奨型」では「。_。_。_。」といった文字列を読み上げさせることで、「標準型」よりも細かい時間単位での間の表現をできるようにしています。ただ、この「_。」を連続して読み上げさせる事で間を開ける時間を制御できるというのはAVSpeechSynthesizerの仕様のスキマを突いた形になっていますので、将来的には使えなくなる可能性が結構あるかなぁと思いまして、「非推奨型」としているという事になります。 また、「標準型」では単位は秒なのですが、非推奨型では単位が回数、なのでそれぞれ単位が違ってきてしまうため、UI上では単位を表示していません。
次に、間の設定での改行の扱いについて解説しておきます。 文章中に複数の改行が連続して現れる場合は、だいたいにおいて段落の切り替えなどが行われることになるため、間は結構開いてくれたほうが良い事が多いです。つまり、改行についても間の設定をできるようにしておいたほうが良いということになります。そこで、改行についても設定できるようにしようかなぁと思ったのですが、間を開ける対象を入力する部分に使っている UITextField を1行入力モードで動かしていると、改行文字を入力することができないのでした。そこで、改行については「<改行>」という文字が入力されていたら、それを改行文字に置き換えて解釈するというルールにしています。
読み替え辞書のリストを取り出す
Version 2.0.0 以降では軽量バックアップファイルの構造が変わっておりますため、以下に示しております Siriショートカット は機能致しません。読み替え辞書のリストを取り出す機能につきましては、取り出せたとしても取り込む方法が無いため、あまり積極的にはサポートする気がありません。 どちらかと言いますと、ユーザ間での読み替え辞書の共有の仕組みの方が興味があるのですが、それはそれで解決できない問題がありますため、手つかずになっております。
iOS 11 辺り(だったと思います)から標準機能として入った「ショートカット」という仕組み(アプリ?)を使って、ことせかい に保存されている読み替え辞書のリストを取り出すショートカットを作ってみました。
ことせかい の軽量バックアップから読み替え辞書を抜き出す
というものがそれなのですが、ちょっと使い方が分かりづらいと思いますので以下に解説しておきます。
まず、このショートカットは ことせかい 側の「設定」→「再ダウンロード用データの生成」→「軽量バックアップを生成する〜」を選択することで生成される軽量バックアップのファイルが必要となります。恐らく「軽量バックアップを生成する〜」を選択した時にメールを送信するような画面になると思いますので、そのメールを自分宛てに送信するなどして生成されたバックアップファイルをあとで読み込めるようにしてください。今回はこの過程で生成されたバックアップデータに保存されている読み替え辞書の部分を取り出すことで、読み替え辞書のリストを印刷しようというのが目的となります。
次に、先程のショートカット(ことせかい の軽量バックアップから読み替え辞書を抜き出す)から、「ショートカットを取得」して自分の端末にショートカットを取り込みます。

ショートカットを取り込む
次に、先程生成した軽量バックアップのファイルを開きます。メールアプリであればファイルのシェアメニューが開くと思います(Gmailアプリなどのアプリではシェアボタン(四角から上向きの矢印が出ているボタン)を押さないとシェアメニューは開かないかもしれません)。そのシェアメニューから「ショートカット」を選択してください。

シェアメニューで「ショートカット」を選択
シェアメニューから「ショートカット」を選択すると、どのショートカットを実行するかを選択する画面になります。
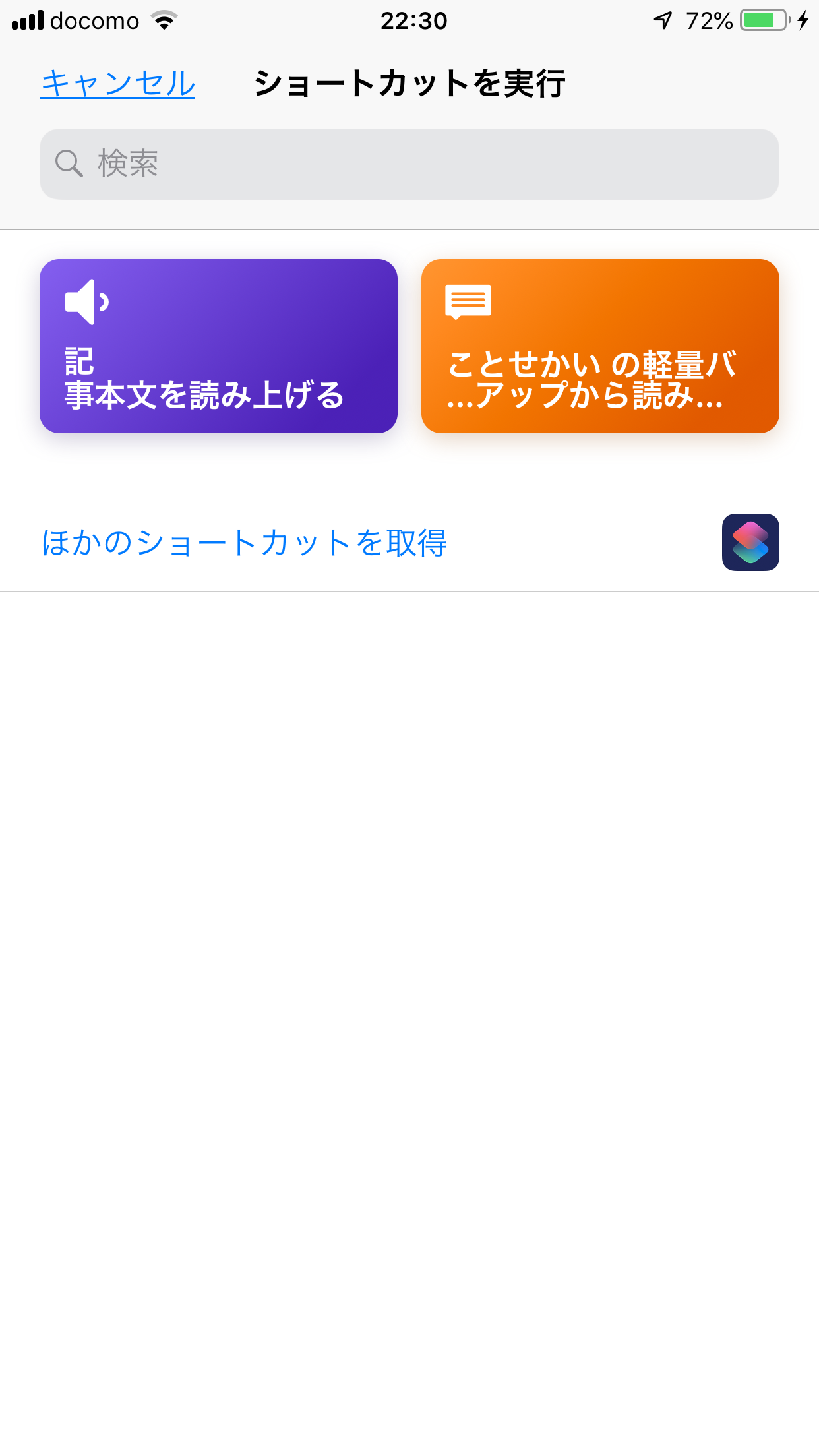
ショートカットの選択画面

読み替え辞書を抜き出した結果
抜き出した結果を書き換えても読み替え辞書への登録には使えませんが、iPhone の小さい画面で見るよりは大きく印刷して見られたほうが良い、というような場合には少しだけ便利に使えるかもしれませんね。
巨大なテキストファイルの取り込み方
Version 2.0.0 以降では、下記に示しておりますような巨大なテキストファイルを取り込む場合に、指定された文字列で分割した物をページとして取り込む事ができるようになりました。 設定項目としては「設定タブ」→「テキスト分割文字列の設定」がそれに当たります。 そのため、以下で示しております Siriショートカット はメンテナンスされなくなっています。
ことせかい はテキストファイルを取り込む機能があるのですが、巨大なテキストファイルだったとしても巨大な一つの章として取り込まれてしまうために、読み上げの開始時にとても時間がかかるなどの問題が発生することがあります。 この問題は複数の章に分けて登録することで回避することができるのですが、テキストファイルをそのまま取り込もうとしても一つの章としてしか取り込めないために回避することが難しい問題となっています。
今回はこの問題に対して
- 巨大なテキストファイルを指定の文字列で分割して
- ことせかい の完全バックアップファイルに偽装したファイルを生成した上で
- ことせかい にそれを読み込ませることで章分けのされた一つの小説として取り込ませる
まず、いくつかの章に区切って読み込ませたい文章をUTF-8エンコーディングのテキストファイルとして作っておいてください。
その時に、章の区切りとして [[改ページ]] という文字列をテキスト中に入れておきます。この [[改ページ]] の部分で章が区切られて取り込まれます。(なお、UTF-8エンコーディングで保存されていないテキストファイルを使用した場合、正常に取り込めないと思われます)
次に、お手元の iOS端末 で複数ページに分割して ことせかい へ読み込むというショートカットを入手してください。
次に、ショートカットアプリを起動して、先程入手したショートカット(「複数ページに分割して ことせかい へ読み込む」)の設定を確認します。 設定を確認するには目的のショートカット(この場合は「複数ページに分割して ことせかい へ読み込む」)の右上にある丸のなかに「…」があるようなアイコンをタップして出てくる手順リストの画面でさらにその右上に出てくる「完了」の下にあるON/OFFスイッチが2つあるようなアイコンをタップすることで設定を書き換えられます。 このショートカット個別の設定の画面で、「共有シートに表示」がONになっていて、その下の「受け入れ種類」にファイルが選択されていることを確認してください。 ここまででショートカットアプリの設定は終了です。
次に、Dropbox などから [[改ページ]] という文字列で区切られたテキストファイルをシェアボタン(Dropboxの場合はエクスポート)で共有しようとしてください。
この時、シェアされるアプリなどのリスト(下側の白黒のものです)の中に ショートカット のアイコンが無い場合は、下側の白黒のリストを右にずらしていって、「…」(その他)というアイコンを選択して「ショートカット」をONにしてください。
シェアされる先に ショートカット を選択すると、先程設定した「複数ページに分割して ことせかい へ読み込む」のショートカットがリストに出てくると思いますので「複数ページに分割して ことせかい へ読み込む」を選択してください。
「複数ページに分割して ことせかい へ読み込む」を選択すると、「小説名を指定してください」というダイアログが出て小説名を入力させられますので、適切な名前に書き換えてOKを押してください。(ここで改行を入れてしまうと正しく動作しませんので改行は入れないようにしてください)
小説名を入力してOKを押した後は、[[改ページ]]ごとに区切られたテキストファイルを生成して、それらを「ことせかい の完全バックアップファイルに偽装したファイル」にまとめた上で ことせかい へ読み込ませようとします。
ここの部分は文章が長ければ長いほど時間がかかると思いますので気長に待っていただければと思います。
「ことせかい の完全バックアップファイルに偽装したファイル」が生成できますと ことせかい が起動してバックアップからの上書き追加の手順に入ります。 こちらも文章が長ければ長いほど時間がかかると思いますので気長に待っていただければ幸いです。
何事もつつがなく終了しますと、本棚に先程入力した小説名として小説が追加されているはずです。
文章側で補佐しながら話者を変える(2021/10)
Version 2.* からはいくつかの話者を定義しての読み分けができるようになりましたため、何人かの登場人物用に話者設定を用意して、それぞれの話者の台詞ごとにその話者を使う、という事もなんとなくできるようになりました。といいますか、一応できないことはない、位の物でして、かなり面倒くさい事をする必要がありますので、良い方法かというとそうでもないかなぁというような物になりますのであまり期待はしないでください。
という前提を理解していただいた上で、やり方は以下のような手順になります。
- 「設定タブ」→「発話設定」に登場人物用の話者の設定を追加する
- 必要となる話者の数と同じ数の「発話設定」を追加します。例えば太郎、二郎、花子の三人であれば、その名前で3つの発話設定を登録します。
- 「設定タブ」→「発話変更設定」にそれぞれの話者の会話文向けの設定を追加する
- 太郎の発話の場合は『太郎:「』からはじめ、『」』で終わる、というような取り決めをする場合、開始文字に『太郎:「』、終了文字に『」』、発話設定に太郎の発話設定を指定した物を作成します。これを、二郎と花子のそれぞれについても作成します。
- 小説の本文側でそれぞれの話者で発話してほしい会話文の開始文字部分を書き換える
- 小説本文側で太郎が発話している会話文について、『「』の部分を『太郎:「』に全て書き換えます。二郎と花子についてもそれぞれ書き換えます。
- 「設定タブ」→「読みの修正」に特殊な会話文の開始文字を読み飛ばす設定を追加する
- 一応上記の3つの設定でそれぞれの会話文についてそれぞれの話者で発話はしてくれるようになるのですが、このままだと会話文の開始文字部分に書き加えたそれぞれの名前を読み上げてからの発話になってしまいますので、その部分は読み飛ばすように読みの修正を追加します。例えば、『太郎:「』から『 』(空白)への読み替えを登録します。二郎と花子についてもそれぞれ同様に登録します。これで、会話文冒頭に追加した話者名を読み上げなくなります。
上記の設定を行った場合、
太郎:「学校いってきまーす」というような文章の会話文部分をそれぞれの話者で発話するようになるはずです。
花子:「いってらっしゃい」
15分後 二郎:「あれ、太郎弁当忘れてら」
花子:「二郎、ちょっと持っていってあげてよ」
二郎:「しょうがねーなー。自転車で追いかけるわ」
太郎くんは15分前に時速3kmで1km先の学校に出発しました。二郎くんは時速6kmで太郎くんを追いかけた場合、二郎くんが太郎くんに追いつくのは何分後か答えなさい。
なお、これらの設定は場合によっては目的の小説以外の小説で悪さをする可能性がないことも無いような気がしますので、「発話変更設定」や「読みの修正」については目的の小説のみの設定(その小説の「詳細」から設定すると良い感じです)に登録する形にしておくと良さそうな気がします。
また、冒頭でも書きましたように、これらの設定や本文への修正はかなり面倒くさいと思われます。特に本文の修正を後からする場合は正直な所面倒くさすぎてやってられなそうな気がすごくします。また、自分で文章を書いているとしても、上記の例では『太郎:「』といった部分の『:』は全角なのか半角なのかを統一しておかないと駄目であるというような話もでてくるような気がします。ということで区切りとなる文字列をどう設定するか、といった事だけでも色々と面倒な話が発生することと思います。なので、一応できないことはないけれど、まぁ普通はやりませんかね、という気分の物だと思ってもらえればと思います。機械学習系の謎技術等でこの会話文は登場人物の誰だ、みたいなのが判定できるようになれば楽にできるようになったりしそうですけれど、多分それができるようになる前に文章中の感情の込め具合辺りができるようになるのが先とかそういう形になりそうな気がしているので、当面の間は人間側から本文に補足情報を入れる(登場人物の名前を入れる)事をしないといけないのではないかなぁと思います。